

Introduction
Image captioning is a functionality that has become increasingly important due to the development of deep learning algorithms. By image captioning, we mean the ability to use computer-based methods to generate a short description or caption for existing images.
We are interested in image captioning because it can benefit several areas of our digital lives, such as e-commerce, education, health, social networking, and more. A particular focus is accessibility, as image captioning can be used to automatically add descriptions to images on websites for people with visual impairments.
A transformer pre-trained for this task is presented below: BLIP.
BLIP stands for Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation and describes a pre-trained transformer that should be applicable to as many images as possible.
Image Captioning: An Example
In the following, we will use an example to explain how image captioning works and what results can be expected.
Image Captioning attempts to combine the fields of computer vision and natural language processing to recognize and contextualize features and objects in images and then have a neural network describe them in natural language. 1 2 3 Often the goal is to keep the description as short as possible, limited to one sentence - but this is not the case for all models and images.
In this context, image annotation can be seen as an extension of image classification, which is simply a matter of assigning images to a set of predefined classes.
This is illustrated below using a selected image:

A possible caption or short description for this image might be
An image of a person walking through the desert on a dune
This is a very simple image. An interpretation is relatively clear here, but does not have to be the same for all images. Image interpretations can vary from person to person, so the neural network can also provide interpretations that do not (directly) make sense.
Implementation
In order to use BLIP, we use both PIL to load the images and transformers to load the neural network with the appropriate parameters:
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGenerationblip_test.py
We can then use the ‘BlipProcessor’ and ‘BlipForConditionalGeneration’ classes to download the parameters for the preprocessor and the neural network.
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large")blip_test.py
In the next step, we can encapsulate the decoding as a function so that we don’t have to repeat the code it contains. The function might look like this:
def decode_image(image):
inputs = processor(image, "a photography of", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)
print(processor.decode(outputs[0], skip_special_tokens=True))blip_test.py
When calling the function, you only need to load the image, convert it to RBG format (if it is not already in that format), and pass it to the function as a parameter.
current_image = Image.open("demo.jpg").convert("RGB")
decode_image(current_image)blip_test.py
Application Examples
Different image types with different levels of complexity are presented below. This is done to make the results more understandable and reproducible.
Images with text
In this section, BLIP will describe images containing types of written words or numbers.

a photography of a bathroom stall with a sign that says small steps are still progress
Although the text here is correct, this issue contains a local restriction to one bathroom stall. This is difficult to support in our opinion.

a photography of a child standing in front of a yellow wall
In this picture, unfortunately, the model only interprets a child in front of a wall, but apparently cannot recognize the text “Believe in yourself”. This is probably due to the combination of perspective and the font of the text. Simple fonts should be used whenever possible.
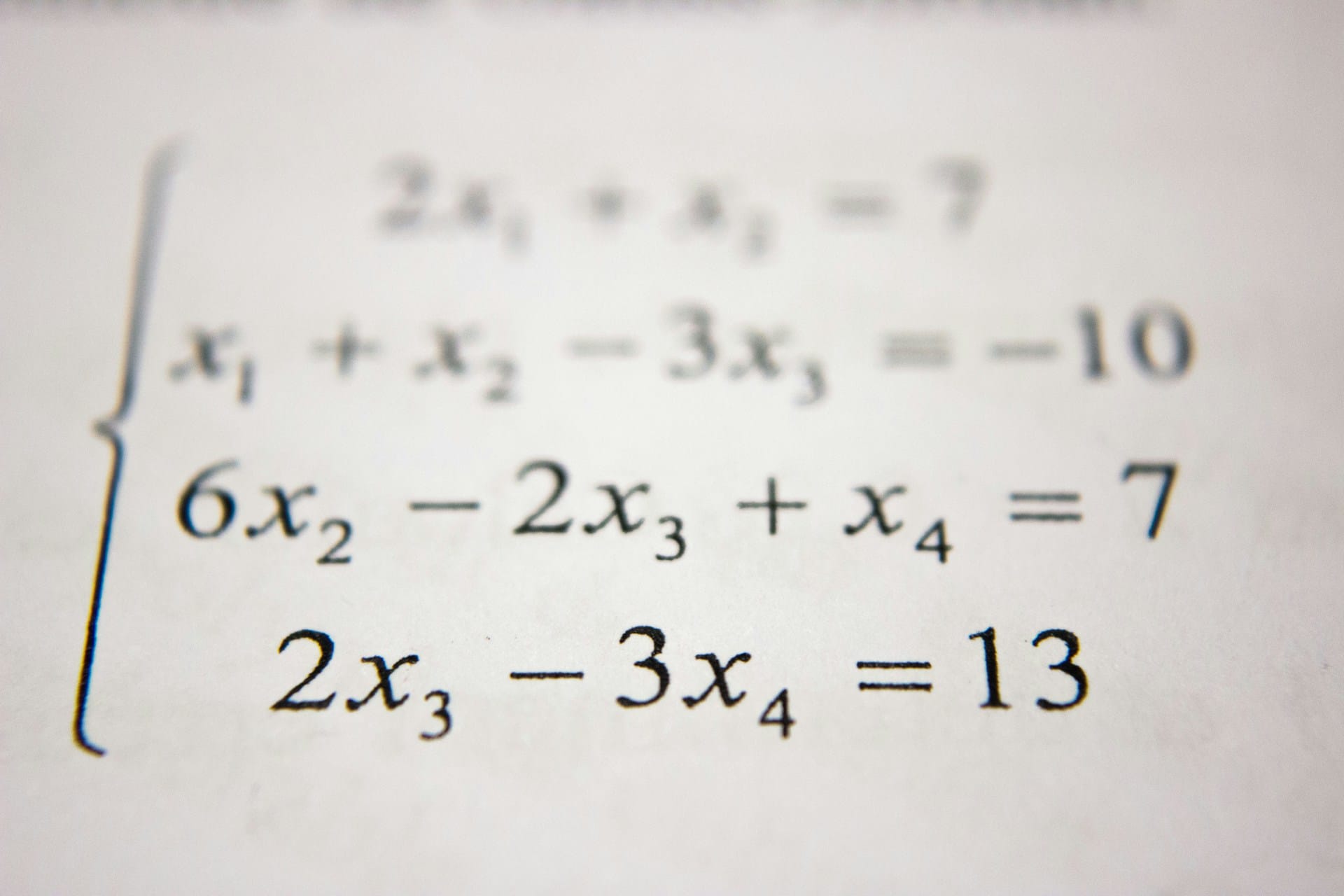
a photography of a piece of paper with a picture of a math textbook
Although the model has not theoretically omitted any essential information in this description, a mathematically trained person can see here that it is not just mathematics. This image describes a system of linear equations. However, this is less important for a rough classification than the level of detail required.
Nature photography
In this section we will look specifically at images from nature. In some examples we can see a high level of complexity due to a large number of plants and/or animals. This should make the task of the model a bit more difficult and give us a better understanding of the capabilities of the neural network.

a photography of a lake surrounded by mountains with the sun setting

a photography of a tree in the fog by a lake

a photography of a blue and green galaxy with stars

a photography of a person swimming in the ocean with a lot of fish
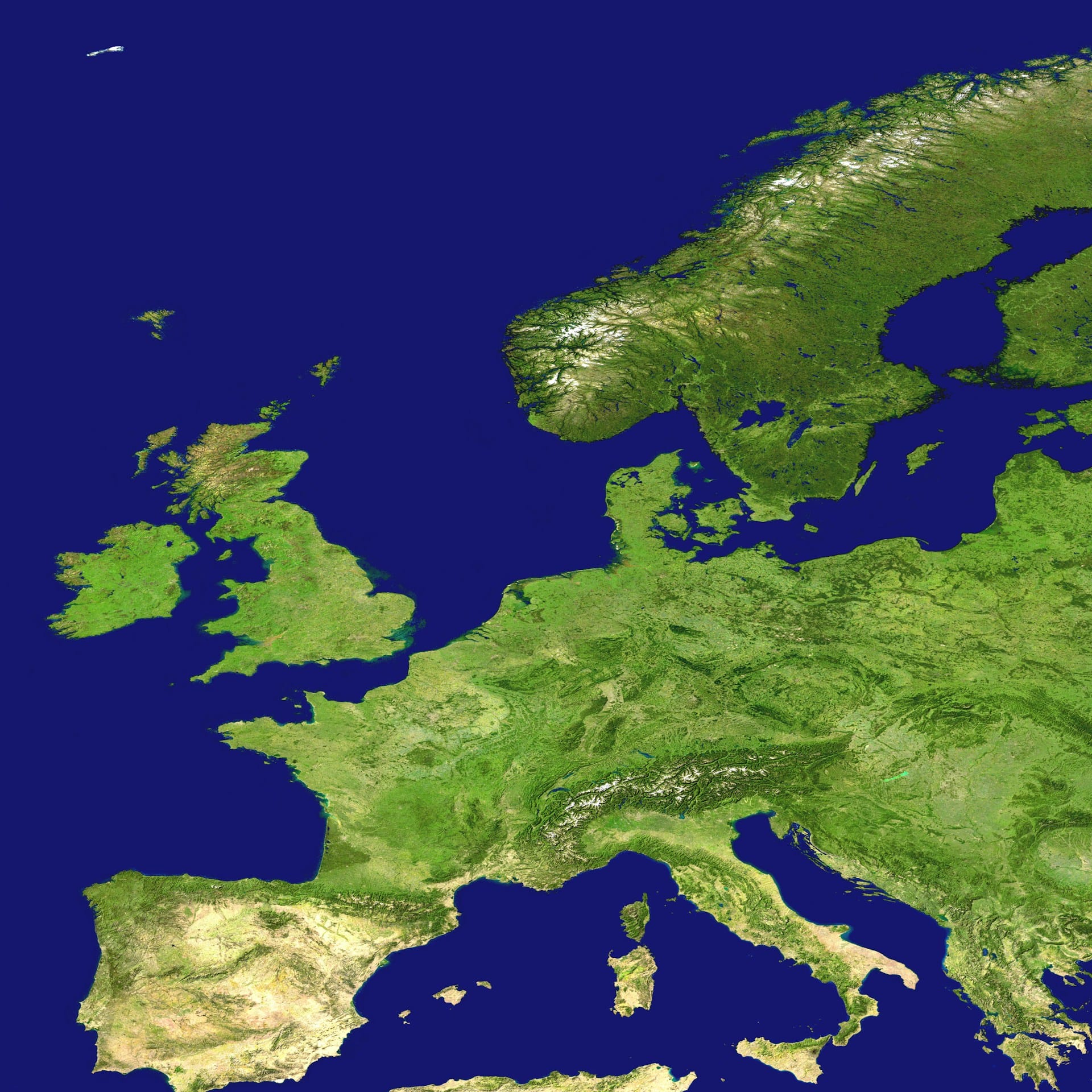
a photography of a map of europe with a plane flying over it
Many of the images shown here are of really good quality, with the exception of the last image. Here we have an anomaly, as an airplane is interpreted into the image, which is clearly not visible. In our opinion, this could also be a satellite image that has been processed to remove clouds.
More complex pictures
In this section we want to raise the level of difficulty a bit. The goal is to use images that leave a lot of room for interpretation (perhaps even necessary for understanding), or that cannot necessarily be clearly defined - here the limits of the model will be further tested after the last section.

a photography of a neon tiger statue in a dark room

a photography of a person standing in front of a red light

a photography of a fire truck spraying water on a fire

a photography of a computer motherboard with many electronic components
Although the short description seems logical at first glance, it is not clear to what extent this is actually a motherboard. However, the rest of the title seems to capture the essence of the image quite well.
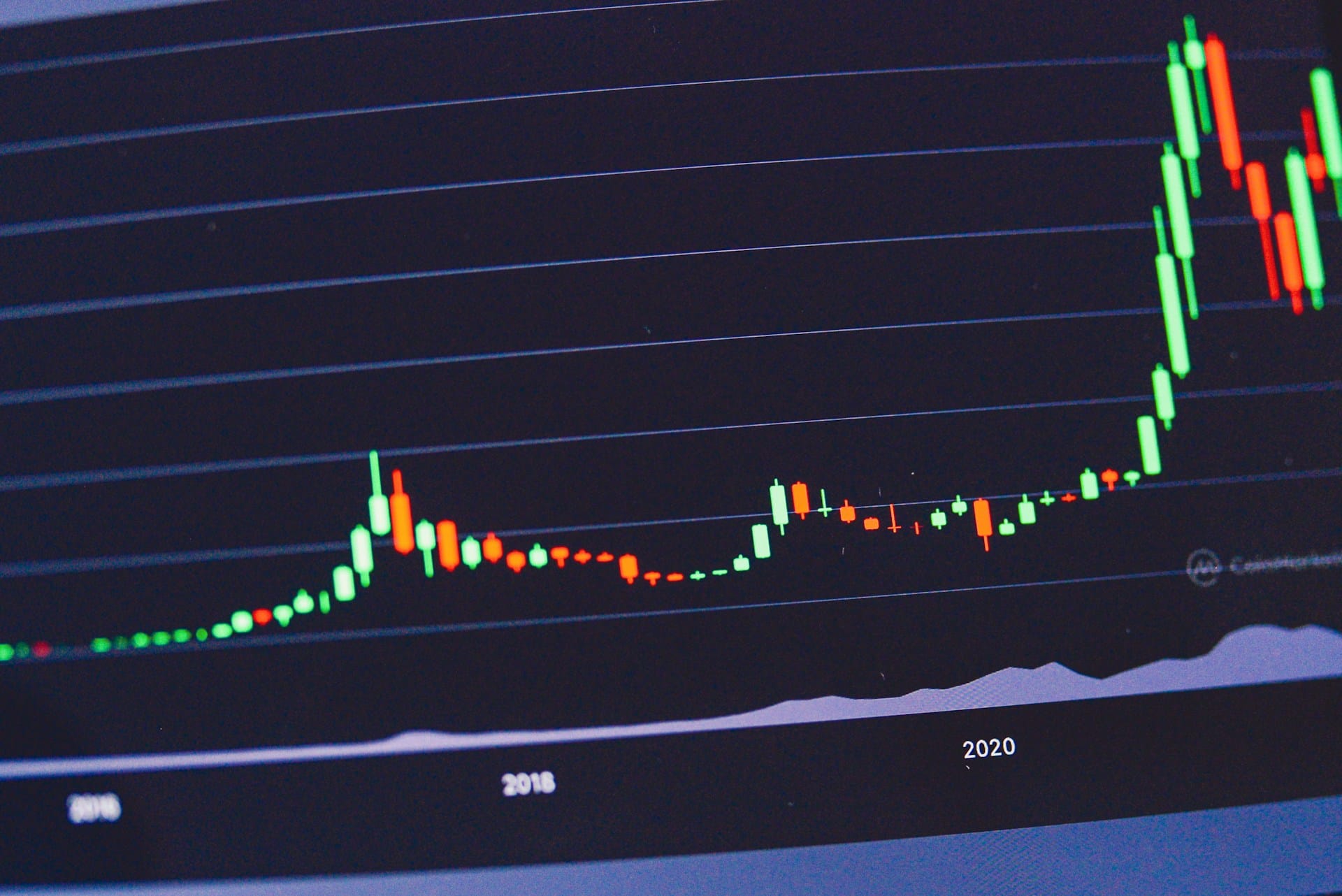
a photography of a computer screen showing a stock chart
In principle, the model has captured the essence of the image well here. At this point, however, we would have liked to see the graph reach higher values on the y-axis as it progresses along the x-axis. Like before, this is a matter of level of detail.

a photography of a group of colorful corals on a white surface
With this image, we must admit that we would not have known exactly what was shown in this image. However, based on the title and subsequent research, this brief description seems to be entirely accurate.
Fields of Application
As we have seen in the previous part of this article, we get good results with BLIP in the area of image captioning. Therefore, we can use BLIP in the following areas, which have already been identified as excellent applications for image captioning systems:
- Improved accessibility: By using image captioning for your own content, you can automatically generate accessibility data for people with visual impairments. This saves time and money. 3 4
- Filter and search content: When applying image tagging to a large number of images, automatic rough classification can be performed based on the output summaries without the need for human supervision or the creation of a test data set.
Depending on the required quality and accuracy of the image classification, further fine classification by a human may be necessary. However, automatic classification by BLIP should provide sufficient accuracy for most applications.
- Social Media: Social media interaction can be increased by changing the description that represents the information in an image. This is particularly interesting for advertising campaigns, but can also be used for business or personal accounts. 4
- Autonomous mobility: To enable a better understanding of autonomous mobility systems, it may be necessary to provide the data with additional details that can be automatically recognized by image annotation systems and added to the dataset. This can potentially shorten the development time of autonomous mobility systems and improve their accuracy. 5
These are just a few examples that are easy to illustrate. Other examples focus on human-machine interaction, industrial applications, and traffic data analysis. 4
TL;DR
In this article we introduced the pre-trained neural network BLIP. BLIP is a neural network that has been trained to automatically generate short descriptions or captions for images. Applications can be found in areas such as accessibility, content filtering and search, autonomous mobility, and many others. In our opinion, the results generated by BLIP are very good. One problem we found with the automatic outputs is that in rare cases information is added that may be realistic but does not seem to be directly verifiable. Also, complex fonts and perspectives in text problems are not always perfectly handled by the model.