Einordnung
In dem letzten Jahrzehnt ist die Thematik Machine Learning immer größer geworden. Ziel des Ganzen war es, Entscheidungen automatisieren zu können oder Prozesse zu optimieren. Neben dem Erfolg von verschiedenen “Machine Learning”-Algorithmen kamen allerdings Probleme in dem Verständnis solcher Algorithmen auf. Ein solcher Algorithmus, welcher dieser Bedingung entspricht, ist der Algorithmus der Entscheidungsbäume (engl.: Decision Trees).
Definition von Entscheidungsbäumen
Bei den Entscheidungsbäumen handelt es sich um ein Unterstützungstool für Entscheidungen, welches eine baumähnliches Modell mit verschiedenen Entscheidungen und deren korrespondierenden Ergebnissen, Kosten und weiteren Informationen enthält. Entscheidungsbäume werden häufig in der Entscheidungsanalyse verwendet, um eine optimale Strategie zu finden, welche ein bestimmtes Ziel unter vorgegebenen Kriterien (bspw. Kostenminimierung) erreicht. 1 2
Weiterhin ist es ein wichtiges Werkzeug im Bereich der [Explainable Artificial Intelligence]. Bei Explainable Artificial Intelligence geht es vor allem darum, Entscheidungen eines “Machine Learning”-Modells entsprechend für den Anwender verständlich zu machen - eine Eigenschaft welche neuronale Netze grundsätzlich nicht besitzen. 3
Ein Entscheidungsbaum besteht aus verschiedenen Knoten (engl. Nodes) und Kanten (engl. Branches). Jeder Entscheidungsbaum beginnt in seiner Struktur mit einer Root Node, welche den Einstiegszustand in die Entscheidungsabfolge darstellt. Dieser spaltet sich danach in mindestens zwei Branches auf, welche die Entscheidung darstellen. Am Ende jedes Branches befindet wieder jeweils eine Node, welche den Ausgangszustand nach der entsprechenden Entscheidung darstellt. So kann sich nach und nach durch die komplette Abfolge der Entscheidungen gearbeitet werden und eine Baumstruktur aufgebaut werden und alle Ausgänge der Entscheidungen modelliert werden. Am Ende des Entscheidungsbaumes befinden sich dann noch die Terminal Nodes, welche eine endgültige Klassifizierung oder Regression darstellen. 4
Häufig wird ein übergeordneter Node (vor der Entscheidung) als Parent Node bezeichnet, aus der Entscheidung ergibt sich dann eine Child Node.
Aufgaben, welche mit Entscheidungsbäumen abgearbeitet werden können, sind beispielsweise eine Klassifikation oder in begrenztem Maße auch Regressionen.
Vorteile von Entscheidungsbäumen
Eine Reihe von Vorteilen sprechen besonders für die oben angesprochenen Anwendungsgebiete: 2 4
- Einfache Interpretierbarkeit: Die Wahr/Falsch-Logik des Entscheidungsbaums sind im Allgemeinen sehr simpel zu verstehen, weiterhin hilft die Struktur mit klarer Richtung der Entscheidungen.
- Wenig Vorbereitung der Daten notwendig: Entscheidungsbäume sind sehr einfach aus Datensätzen zu generieren. Algorithmen zur Generierung von Entscheidungsbäumen sind grundsätzlich in der Lage, mit verschiedenen Variablen (diskret, stetig) umzugehen.
- Große Flexibilität: Entscheidungsbäume sind sowohl für den Einsatz bei der Klassifizierung als auch bei der Regression geeignet.
Nachteile von Entscheidungsbäumen
Mit der Implementierung von Entscheidungsbäumen kommen eine Reihe von Nachteilen zum Tragen: 2 4
- Anfällig gegenüber Overfitting: Bei genauem Fitten der Daten auf dem Labeln entsteht häufig das Problem, dass der Entscheidungsbaum sehr gut auf den spezialisierten Trainingsdaten passt, allerdings in der Realität nicht gut genug generalisiert.
- High Variance Estimators: Kleine Änderungen in den Daten können komplett unterschiedliche Entscheidungsbäume nach sich ziehen.
- Computerintensive Generierung: Algorithmen zur Generierung von Entscheidungsbäumen benötigen viel Zeit und Computerresourcen, um die entsprechenden Entscheidungsbäume auf den Datensätzen zu erzeugen.
Aufbauen eines Entscheidungsbaumes
Häufig wird man als Nutzer einen gewissen Datensatz mit mehreren Eingangsvariablen besitzen und eine Klassifikation anhand der Daten generieren wollen. Somit hat ist am Anfang nur der Anfangsknoten mit keinen Einschränkungen gegeben, nach und nach soll hierbei der Entscheidungsbaum generiert werden. Hierzu sind Kriterien notwendig, um Splits in den Datensätzen zu generieren, welche optimale Entscheidungen für eine Einteilung finden.
Um sinnvolle Splitting Criterion zu betrachten, ist vorher der Begriff der Entropie notwendig.
Entropie
Bei der Entropie handelt es sich um einen Begriff auf der Informationstheorie, welcher die Inhomogenität oder Unreinheit von einer Stichprobe misst. Es ist definiert als
Hierbei stellt den Datensatz, die Klassen aus und das Verhältnis der Daten in Klasse zu den gesamten Datenpunkten dar.
Die Werte der Entropie beschränken sich auf . Wenn alle Datenpunkte aus dem Datensatz zu einer einzigen Klasse gehören, dann wird die Entropie automatisch zu null. Dies folgt daraus, dass hierbei keine Unreinheit mehr vorliegt. Als Ziel unseres Entscheidungsbaumes ist also ableitbar, dass in den Terminal Nodes also möglichst eine Entropie von null vorliegen sollte.
Alternativ kann die Gini Impurity definiert werden durch:
Äquivalent zur Entropie sollte diese möglichst gegen null laufen.
Splitting Criterion
Um die Daten entsprechend aufzutrennen, könnten Sie den Information Gain verwenden, welcher wie folgt definiert ist:
Die Menge ist definiert als 5
Der Information Gain beschreibt den Unterschied der Entropie vor und nach dem Split. Ziel ist es, die Entropie nach dem Split zu minimieren, damit die Informationen dort möglichst homogen sind.
Pruning
Bei der Generierung von verhältnismäßig exakten Entscheidungsbäumen ergibt sich häufig das Problem, dass diese sehr groß sind und somit die entstehenden Entscheidungen mit vielen kleinen Schritten verbunden sind und die Entscheidungen nicht mehr unbedingt klar nachvollziehbar sind. Um dies zu vermeiden, existiert das Konzept vom Decision Tree Pruning, welches die Länge des Entscheidungsbaumes verkürzen soll.
Die Idee ist es, Sektionen und nicht-kritische Zweige des Baumes “abzuschneiden”, ohne dabei große Präzisionsverluste in der zugrundeliegenden Aufgabe zu haben. Dieses Verfahren wird meist auf bereits generierte Entscheidungsbäume angewandt.
Problematisch ist hierbei, dass nicht klar ist, wie groß der entsprechende Baum später wird ohne große Fehler auf dem Datensatz zu erzeugen. Ein zu kleiner Baum kann unter Umständen bestimmte Nuancen des Datensatzes nicht mehr richtig einschätzen, während zu große Bäume üblicherweise unter Overfitting leiden. Dies ist also ein Optimierungsproblem, welches sich aus der Natur des Projektes oder der Aufgabe ergibt. 6
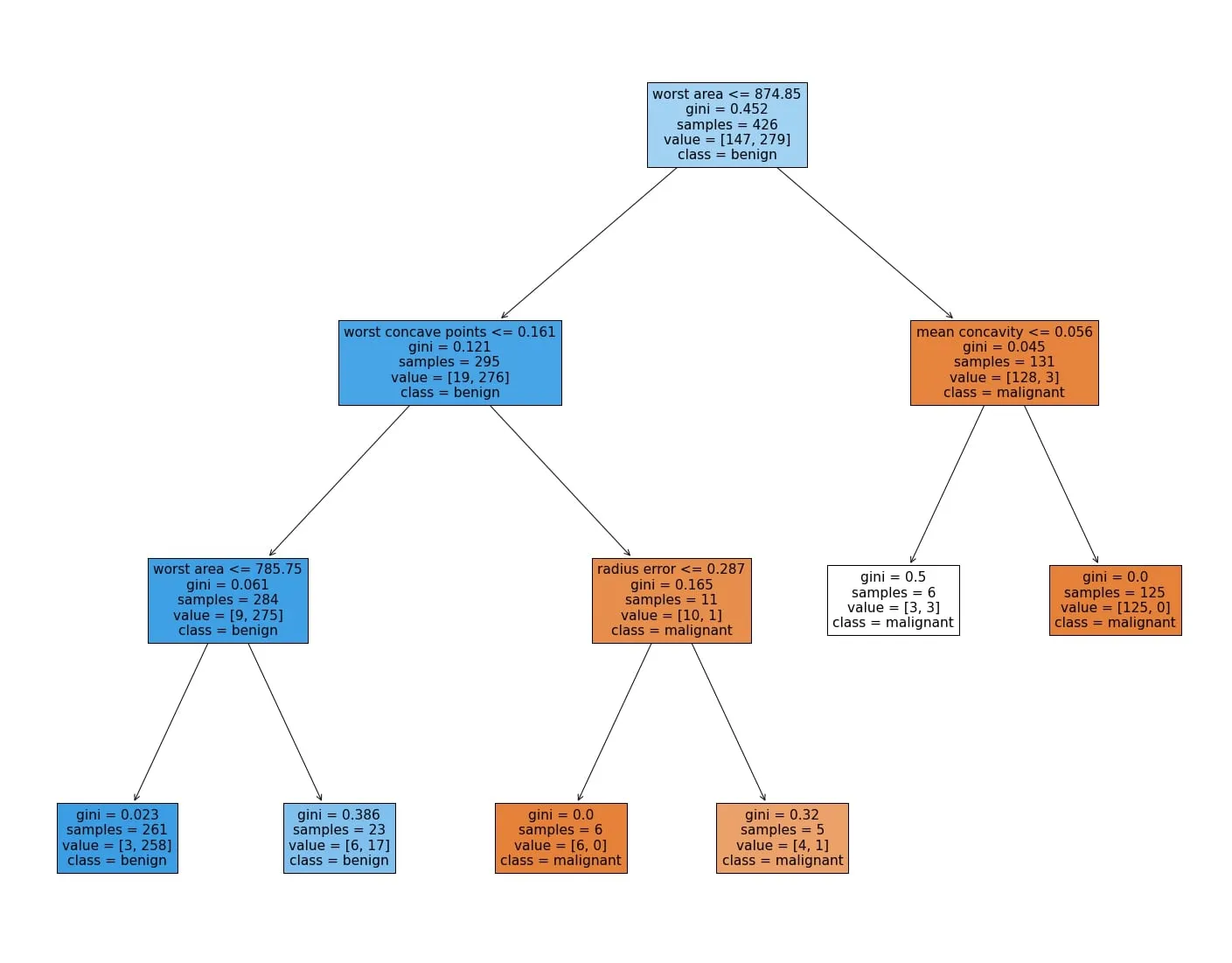
Anwendungsbeispiel
Aus dem Datensatz zur Untersuchung von Brustkrebs kann ein Decision Tree Classifier trainiert werden. Ein generierter Entscheidungsbaum kann hierunter gefunden werden.