
Einordnung
Seit vielen Jahren arbeitete die Forschung bereits an der Lösung von Reinforcement Learning-Aufgaben. Einer der ersten Algorithmen, welcher die Forschung im Gebiet von Deep Reinforcement Learning hervorbrachte, wardas Deep Q-Network (kurz: DQN). 1 Später wurde dieser Algorithmus ebenfalls von Deepmind verwendet, um an Atari-Spielen zu spielen und vergleichbare oder bessere Performance als Menschen hervorzubringen. 2 3
Mathematische Grundlagen
Grundidee des Deep Q-Networks
Für eine Einleitung in die Terminologie von “Reinforcement Learning”-Problemen, kann diese Webseite empfohlen werden.
Die Idee des Deep Q-Networks ist es, in jedem Schritt der Umgebung die Aktion zu lernen und wählen, mit welcher der maximale Return assoziiert wird. Der Return ist definiert als
Der Return wird manchmal auch als Expected Return oder Discounted Reward bezeichnet.
Hierbei stellen den Discount Factor und den Reward durch die Umgebung im Zeitschritt dar. Der Discount Factor ist eine Größe, welche darstellt, wie lange und stark Rewards eine Auswirkung auf den Return haben.
Für bleiben Rewards immer im Return und klingen nicht ab, für haben die Rewards relalistisch nur für wenige (oder extrem: einen) Zeitschritt eine Auswirkung auf den Return.
Durch die Tatsache, dass versucht wird durch das neuronale Netz einen Return zu approximieren, kann man hier anstatt des neuronalen Netzes von einem Funktionsapproximator sprechen. Dies kommt daher, dass das neuronale Netz versucht, die Rewards für alle möglichen Aktionen abhängig von der Observation bestmöglich zu lernen. Man kann also das neuronale Netz als
darstellen, wobei die Mengen der verschiedenen Observationen (beispielsweise verschiedene Winkel bei Robotern) und die Mengen der verschiedenen Aktionen (beispielsweise bewege Arm 1 oder 2) sind.
Update-Formel
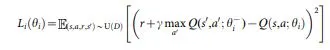
In dieser Formel ist erkennbar, dass versucht wird die Loss-Funktion mit den Netzwerkparametern des Deep Q-Networks zu minimieren. Dies versucht man über Mean Squared Error. Klassischerweise wird dies nicht nur in dem aktuellen Schritt, sondern auch über ein Experience Replay durchgeführt. 4 5 6
Das Experience Replay beinhaltet alte und neue Durchläufe von Episoden. Es soll verhindern, dass das Netzwerk Catastrophic Forgetting durchläuft; das Netzwerk vergisst also jeglichen Fortschritt den es gemacht hat. Es gibt eine Reihe von weiteren Funktionalitäten, welche in späteren Algorithmen implementiert wurden und ebenfalls versuchen Catastrophic Forgetting zu verhindern.
Hierzu samplt man (üblicherweise über eine diskrete Gleichverteilung der Indizies) Informationen über alte Durchläufe, wobei allgemein keine Episoden sondern Schritte extrahiert werden. Eine Alternative hierzu findet sich in Mögliche Verbesserungen.
Samplen aus dem Experience Replay hat den Vorteil, dass Informationen zwischen mehreren verschiedenen Episoden entkoppelt werden und dadurch üblicherweise bessere Traininsverhalten entstehen. Zusätzlich hält man auch mehr Informationen pro Trainingsepisode (vor allem in frühen Episoden im Training bei vielen Umgebungen) durch mehr betrachtete Schritte in der Umgebung, was die Qualität des berechneten Gradientens erhöht. Dies kann nachteilig sein, wenn der aktuell beste Schritt von den vorherigen Schritten abhängt; Deep Q-Networks sind im Allgemeinen allerdings nicht sonderlich gut in solchen Umgebungen aufgrund schlechter Informationszusammenführung zwischen mehreren Schritten. Hier verwendet man meist n-Step-Agents wie das Deep Recurrent Q-Network.
Weiterhin wird Reward Clipping verwendet, welches mittels einer linearen Transformation auf transformiert. Dies umgeht zwei Probleme:
- Neuronale Netze benötigen viele Lernschritte, um Gewichte aufzubauen, um größe Werte mit akzeptabler Fehlertoleranz zu generieren. Wenn der Reward verkleinert wird, beschleunigt dies das Training.
- Umgebungen mit verschieden großen Rewards (beispielsweise: erst , später ) sind instabiler. Reward Clipping verhindert das Entstehen dieses Problems.
Implementierung mittels Tensorflow
Problem
In dieser Implementierung wird der Agent versuchen, das CartPole-Problem von OpenAI zu lösen. Hier wird eine Categorical Policy verwendet. Für weitere Umgebungen zum Training von Agenten, siehe hier.
Pseudocode

Code
Wir beginnen mit allen notwendigen Imports:
import datetime
import math
import gym
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from collections import deque
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense, InputLayer
from tensorflow.python.keras.optimizer_v2.adam import Adam
Hierbei sei angemerkt, dass diese Implementierung mit einer Tensorflow-Version von 2.12.0 getestet wurde. Bei niedrigeren Versionen kann es sein, dass die Imports von
import tensorflow.python.keras.[...] zu import tensorflow.keras.[...] geändert werden müssen.
Zunächst wird das Experience Memory implementiert.
class ExperienceMemory:
def __init__(self, memory_length: int=10000, batch_size: int=64, nonunique_experience: bool=True):
self.memory_length = memory_length
self.batch_size = batch_size
self.nonunique_experience = nonunique_experience
# ** Initialize replay memory D to capacity N **
self.cstate_memory = deque([], maxlen=self.memory_length)
self.action_memory = deque([], maxlen=self.memory_length)
self.reward_memory = deque([], maxlen=self.memory_length)
self.done_memory = deque([], maxlen=self.memory_length)
self.pstate_memory = deque([], maxlen=self.memory_length)
def record(self, cstate, action, reward, done, pstate):
# Convert states into processable objects
cstate = tf.expand_dims(tf.convert_to_tensor(cstate), axis=0)
pstate = tf.expand_dims(tf.convert_to_tensor(pstate), axis=0)
# Save data
self.cstate_memory.append(cstate)
self.action_memory.append(action)
self.reward_memory.append(reward)
self.done_memory.append(done)
self.pstate_memory.append(pstate)
def return_experience(self):
# Retrieve experience
batch_indices = np.random.choice(len(self.cstate_memory), size=self.batch_size, replace=self.nonunique_experience)
batch_cstate = np.array(list(self.cstate_memory))[batch_indices, :]
batch_action = np.take(list(self.action_memory), batch_indices)
batch_reward = np.take(list(self.reward_memory), batch_indices)
batch_done = np.take(list(self.done_memory), batch_indices)
batch_pstate = np.array(list(self.pstate_memory))[batch_indices, :]
# Convert experience into respective tensorflow tensors
cstates = tf.squeeze(tf.convert_to_tensor(batch_cstate))
actions = tf.convert_to_tensor(batch_action)
rewards = tf.convert_to_tensor(batch_reward, dtype=tf.float32)
dones = tf.convert_to_tensor(batch_done, dtype=tf.int64)
pstates = tf.squeeze(tf.convert_to_tensor(batch_pstate))
return (cstates, actions, rewards, dones, pstates)
def flush_memory(self):
self.cstate_memory.clear()
self.action_memory.clear()
self.reward_memory.clear()
self.done_memory.clear()
self.pstate_memory.clear()
Das Experience Memory stellt einen einfachen Container für Erinnerungen vergangener Transitionen dar. Bei return_experience wird zusätzlich die Dimensionalität des
Outputs angepasst, damit das Modell dies später ohne Probleme akzeptiert.
Nun schreiben wir unsere Klasse DQNAgent. Diese beinhaltet die Funktionen __init__, compute_action, update_epsilon_parameter, store_step, get_batch und train:
class DQNAgent:
def __init__(self, observation_size, action_size):
self.observation_size = observation_size
self.action_size = action_size
# Network parameters
self.memory_length = 26000
self.alpha = math.pow(10, -3)
self.gamma = 0.951
self.epsilon = 0.8
self.min_epsilon = 0.05
self.epsilon_decay = 0.005
self.batch_size = 64
self.nonunique_experience = True
# ** Initialize replay memory D to capacity N **
self.experience_memory = ExperienceMemory(self.memory_length, self.batch_size, self.nonunique_experience)
# ** Initialize action-value function Q with random weights **
self.model = Sequential([
InputLayer(input_shape=self.observation_size, name="Input_Layer"),
Dense(units=128, activation='relu', name='Hidden_Layer_1'),
Dense(units=self.action_size, activation='linear', name='Output_Layer')], name="Deep_Q-Network")
self.model.compile(loss="mse", optimizer=Adam(learning_rate=self.alpha))
# self.model.compile(loss='categorical_crossentropy', optimizer = Adam(learning_rate=self.alpha1))
self.model.summary()
# Define metrics for tensorboard
self.score_log_path = 'logs/' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
self.score_writer = tf.summary.create_file_writer(self.score_log_path)
Die Kommentare in dieser Funktion sind relativ selbsterklärend. Der Konstruktor verlangt die Dimensionalität der Eingangs- und Ausgangswerte, welche später für die Initialisierung des ersten und letzten Layers des neuronalen Netzes verwendet werden. Die Hyperparameter sind aus Erfahrung und verschiedenen Hyperparameteroptimierungen entstanden, eine Veränderung des Modells benötigt unter Umständen eine andere Konfiguration der Hyperparameter. Weiterhin wird das Experience Replay initialisiert und eine I/O-Objekt für Tensorboard erstellt, welches den Trainingsprozess visualisiert. Für Tensorflow ist Tensorboard eine der besten Packages, um Metriken während des Trainingsprozesses darzustellen.
In vielen Blogs wird hierbei auch auf Seaborn oder Matplotlib verwiesen. Matplotlib erwies sich immer als einfache und robustes Werkzeug für Visualisierungen jeglicher Art, Seaborn wirbt damit der modernere Nachfolger vieler statistischer Visualisierungstools zu sein.
Bei Deque handelt es sich um ein dynamisches Array, welches eine bestimmte Maximallänge aufweist. Sollten nach Erreichen der maximalen Länge Einträge hinzugefügt werden, werden die letzten Einträge durch die neuen Einträge ersetzt.
def compute_action(self, observation, evaluation: bool=False):
if (np.random.uniform(0, 1) < self.epsilon and evaluation == False):
return np.random.choice(range(self.action_size)) # ** With probability epsilon select a random action a_t **
else:
observation = np.expand_dims(observation, axis=0)
Q_values = self.model([observation])
return np.argmax(Q_values) # ** Otherwise select a_t = argmax(Q) **
def update_epsilon_parameter(self):
self.epsilon = max(self.epsilon * math.exp(-self.epsilon_decay), self.min_epsilon)
Weiter geht es mit der Funktion für die Auswahl der Aktion unter der aktuellen Observation. Hierbei wird ein Epsilon Greedy Scheme verwendet, welches mit Wahrscheinlichkeit
eine zufällige Aktion auswählt, mit Wahrscheinlichkeit wird hierbei die Aktion durch das Netzwerk ausgewählt. Dieses Schema
dient dem Dilemma zwischen Exloration vs Exploitation, welches im Reinforcement Learning maßgeblich ist. Im Verlaufe des Trainings sollte nach und nach sinken,
ohne unter einen Schwellenwert zu sinken. Dies wird durch die Funktion update_epsilon_parameter hier garantiert. Die Funktion compute_action besitzt hier
das zusätzliche Argument evaluation: bool=False, welches die Aktivität des Epsilon Greedy Schemes steuert.
def store_step(self, cstate, action, reward, done, pstate):
self.experience_memory.record(cstate, action, reward, done, pstate)
Als Nächstes kommt die Funktion, welche mit dem Experience Replay interagiert. Die Methode store_step bekommt ein Tupel aller Informationen pro Zeitschritt (und der Observation des
darauffolgenden Schrittes) übergeben und speichert diese im Experience Replay. In diesem Fall könnte auch ein direktes Interface implementiert werden, dies stellt allerdings eine
allgemeinere Schnittstelle dar. Dies kann bei Bedarf intern modifiziert werden, ohne umliegenden Code weiter anpassen zu müssen (wie beispielsweise später bei der Training-Loop).
def train(self): # **For each update step**
# ** Sample random minibatch of transitions from D**
b_cstate, b_action, b_reward, b_done, b_pstate = self.experience_memory.return_experience()
# ** Set y_j **
prediction_model_p = self.model(b_pstate)
q_value_network = np.zeros((self.batch_size,))
b_done = b_done.numpy()
max_pred = np.max(prediction_model_p, axis=1)
q_value_network = (1 - b_done) * self.gamma * max_pred
target_q_p = np.add(b_reward, q_value_network)
# **Perform gradient descent step on Q**
self.model.train_on_batch(b_cstate, target_q_p)
# self.model.fit(b_cstate, target_q_p, verbose=0)
Hier kommt das Herzstück des eigentlichen Algorithmus. In dieser Methode updaten wir das Netzwerk aufgrund eines Teiles der Informationen, welche wir im Laufe des Trainings gesammelt haben.
Diese Funktion ist die Umsetzung des Update-Schritts im Pseudocode. Unten drunter ist die Zeile self.model.fit(b_cstate, target_q_p, verbose=0) auskommentiert, da sich meist die Methode
self.model.train_on_batch(b_cstate, target_q_p) als bessere Trainingsmethode herausgestellt hat. Es ist möglich, dass mehrere Epochen hierauf auch bessere Ergebnisse liefern, aktuell
trainiert das Netzwerk nur auf einer Episode.
def training_loop(env, agent: DQNAgent, max_frames_episode: int):
current_obs, _ = env.reset()
episode_reward = 0
for j in range(max_frames_episode):
action = agent.compute_action(current_obs)
next_obs, reward, done, _, _ = env.step(action)
next_obs = np.array(next_obs)
agent.store_step(current_obs, action, reward, done, next_obs)
current_obs = next_obs
episode_reward += reward
if done:
agent.update_epsilon_parameter()
break
return episode_reward, agent
def evaluation_loop(env, agent: DQNAgent, max_frames_episode: int):
current_obs, _ = env.reset()
evaluation_reward = 0
for j in range(max_frames_episode):
# ** Execute action a_t in emulator and observe reward r_t and image x_{t+1}
action = agent.compute_action(current_obs, evaluation=True)
next_obs, reward, done, _, _ = env.step(action)
next_obs = np.array(next_obs)
# **Storing all information about the last episode in the memory buffer**
agent.store_step(current_obs, action, reward, done, next_obs)
# Reseting environment information so that next episode can handle the previous information
current_obs = next_obs
evaluation_reward += reward
if done:
break
return evaluation_reward, agent
Es folgen die beiden Funktionen zum Training und Validieren des Lernfortschrittes. Die Funktion training_loop ist einzig dazu gedacht immer wieder wiederholt zu werden und so dem
Agenten mehr Informationen zuzuführen, während dieser sich durch die Umgebung “bewegt”.
Hinweis: In dieser Implementierung findet kein Update-Schritt nach jedem Zeitschritt statt, sondern nach jeder Episode.
Die Funktion evaluation_loop tut im Prinzip nichts anderes, außer dass diese keine Exploration beinhaltet.
n_episodes, max_frames_episode, avg_length, evaluation_interval = 5000, 500, 50, 10
episodic_reward, evaluation_rewards = [], []
env = gym.make("CartPole-v1")
n_actions = env.action_space.n
observation_shape = env.observation_space.shape[0]
tf.random.set_seed(69)
np.random.seed(69)
agent = DQNAgent(observation_shape, n_actions)
eval_reward, episode_reward = 0, 0
# agent.score_writer.init()
for i in range(n_episodes):
# **Observing state of the environment**
episode_reward, agent = training_loop(env=env, agent=agent, max_frames_episode=max_frames_episode)
print("Training Score in Episode {}: {}".format(i, episode_reward))
if (i % evaluation_interval == 0):
# Evaluation loop
eval_reward, agent = evaluation_loop(env=env, agent=agent, max_frames_episode=max_frames_episode)
print("Evaluation Score in Episode {}: {}".format(i, eval_reward))
with agent.score_writer.as_default():
tf.summary.scalar('Episodic Score', episode_reward, step=i)
if (i % evaluation_interval == 0):
tf.summary.scalar('Evaluation Score', eval_reward, step=i)
episodic_reward.append(episode_reward)
agent.train()
Hier findet sich die Initialisierung aller notwendigen Parameter für die Training-Loop und die Training-Loop selbst. Hierbei wurden Seeds verwendet, damit das Training reproduzierbar ist, dies sollte in einer Unternehmensumgebung entfernt werden, um die möglichen Ergebnisse flexibel zu halten. Weiterhin erkennt man hier die Write-Vorgänge von Tensorboard. Abhängig vom System, kann es notwendig sein, den Writer zu initialisieren. Meist sollte dies allerdings auch ohne diese Initialisierung funktionieren. Eine Visualisierung der Trainings-Performance folgt:
Hier ist erkennbar, dass innerhalb von 1000 Episoden ( Minuten CPU-Time) sich die Performance des Modells im Vergleich zum Beginn verbessert hat. Es besteht mehr Potenzial bezüglich der Performance, bei angepassteren Architekturen und noch besser angepassten Hyperparametern.
Hinweis: Trainingsperformance kann sich von Gerät zu Gerät und entsprechenden Seeds teilweise stark unterscheiden. Allgemeine Reproduzierbarkeit von solchen Ergebnissen ist im Allgemeinen nicht garantierbar.
Hinweise bei der Implementierung
- Tensorflow stellt die Funktionalität
Model.predict(observation)anstelleModel(observation)bereit. Siehe hier hierzu. Problematisch hierbei ist, dass diepredict-Funktion eine bedeutend größere Laufzeit aufweist. Sofern sollteModel(observation)verwendet werden, außer es gibt besondere Gründe, warum dies nicht geschehen sollte.
Alternativen dieses Algorithmus
Wie in der Quelle 2 beschrieben, hat dieses Netzwerk in seiner Grundform Probleme, das Q-Target zu approximieren. Der Grund darin liegt, dass dies nicht konstant ist und das Netzwerk so Instabilitäten im Lernprozess aufweisen kann.
Das Paper liefert als Erweiterung ein Frozen Target-Network. Dieses wird immer alle Episode updated und verwendet, um das Q-Target zu berechnen. Das Paper zeigt hierbei, dass diese Änderung bedeutend performantere Ergebnisse nach sich zieht, als dies in der Grundform der Fall ist.
Ein solches Update der Netzwerkparameter des Frozen Networks alle Episoden wird auch als Hard Update bezeichnet.

Weiterhin einmal ein Vergleich zwischen der mittleren Performance der beiden Algorithmen:
Hinweis: Trainingsperformance kann sich von Gerät zu Gerät und entsprechenden Seeds teilweise stark unterscheiden. Allgemeine Reproduzierbarkeit von solchen Ergebnissen ist im Allgemeinen nicht garantierbar.
Zu erwarten wäre hier eine Verbesserung in der Trainingsperformance. Diese kann hier nicht gesehen werden. Trotz dieser Tatsache ist eine Reduzierung der Varianz erkennbar.
Implementierung mittels Pytorch
Nach der ausführlichen Implementierung mittels Tensorflow, wird auf diese Webseite verwiesen. Dort findet sich eine verhältnismäßig gute Implementierung mittels Pytorch, welche technisch gesehen die Ergebnisse reproduzieren können sollte.
Mögliche Verbesserungen
Eine Möglichkeit den Trainingsprozess zu verbessern, es Importance Experience Replay zu verwenden. Importance Experience Replay verbessert den Prozess, indem die diskrete Gleichverteilung zum Samplen der Informationen aus dem Experience Replay verworfen wird. Stattdessen wird eine Wahrscheinlichkeit für jeden Zeitschritt im Experience Replay berechnet, welche abhängig von der Abweichung zwischen vorhergesagter und tatsächlichem Return ist. Hierdurch werden potenziell wichtige Zeitschritte für den Agenten häufiger wiederholt, anstatt Zeitschritte, welcher der Agent bereits gut approximiert.
Ausblick
Das Deep Q-Network ist zwar nicht mehr der aktuellste oder modernste Algorithmus zum Lösen von “Reinforcement Learning”-Problemen, allerdings liefert es die Grundlage für viele fortgeschrittene Algorithmen wie D3QN oder Actor-Critic-Architekturen (wobei ein DQN das Paar aus Observation und Aktion “bewertet”). Dementsprechend ist das Verständnis für diesen Algorithmus zentral zum fortgeschrittenen Verständnis von fortgeschrittenen “Reinforcement Learning”-Algorithmen.
Änderungen
-
[21.10.2022] Einfügen von Informationen bezüglich Deque, Einfügen von Informationen bezüglich des Frozen Target-Networks. Update des Codes, damit dieser mit Gym (Version 0.26) kompatibel ist. Zusätzlich Auslagerung des Experience Replays aus dem Agenten heraus.
-
[23.01.2023] Einfügen von interaktiven Diagrammen; Hinzufügen der Informationen bezüglich Reproduzierbarkeit.