
Die Texte in diesem Artikel wurden teilweise mit Hilfe künstlicher Intelligenz erarbeitet und von uns korrigiert und überarbeitet. Für die Generierung wurden folgende Dienste verwendet:
Einführung
Bilder spielen in unserem digitalen Leben eine immer größere Rolle. Sei es in sozialen Netzwerken, in Newslettern und Nachrichten oder bei einer Google-Suche, wir kommen sehr häufig mit Bildern in digitaler Form in Kontakt. Aus dieser Menge an möglichen und nützlichen Dateien ergibt sich die Nützlichkeit von Question Answering, um bestimmte Fragen aus einer Reihe von Bildern beantworten zu lassen. Dies kann aus Gründen der Zeitersparnis, Zugänglichkeit, Datenanalyse oder einer anderen Aufgabe nützlich sein, welche durch die Nutzer:innen bestimmt werden kann.
Im heutigen Artikel wollen wir ein neuronales Netz vorstellen, das für genau diese Aufgabe trainiert wurde: Matcha-Quarta von Google.
Danksagung
An dieser Stelle wollen wir auf die Arbeit des Teams von ourworldindata hinweisen. Dieses Team stellt hochqualitative Statistiken zur Verfügung, welche auf Schwierigkeiten und Probleme aufmerksam machen und eine detailliertere Analyse ermöglichen.
To make progress against the pressing problems the world faces, we need to be informed by the best research and data. Our World in Data makes this knowledge accessible and understandable, to empower those working to build a better world.
Durch die Veröffentlichung verschiedenster Statistiken, möchte das Team aufzeigen, dass nicht alle Probleme auf der Welt immer schlimmer werden - sondern Situationen sich kontinuierlich verbessern. 1 2 Durch die Verwendung der öffentlich nutzbaren Statistiken auf dieser Webseite möchten wir uns bei dem Team bedanken.
Question Answering
Um eine gemeinsame Grundlage zu schaffen, möchten wir zuerst eine Definition der Aufgabe Question Answering in dem Kontext von Matcha-Quarta liefern, bevor wir in die eigentliche Verwendung und Resultate des Modells einsteigen.
Beim Question Answering geben wir dem Modell zwei miteinander verbundene Dinge vor:
-
Ein Bild und
-
eine Frage, welche sich auf das Bild bezieht.
Aufgabe des Modells ist es nun, anhand beider Komponenten eine Antwort auf die Frage zu bestimmen, indem es Inhalt und Kontext der Bilder versucht zu verstehen. Abhängig von der Genauigkeit der Trainingsdaten und der Modellparameter können Antwortgenauigkeit hierbei variieren. Obwohl es noch weitere Formen und Abwandlungen des Question Answerings gibt, beschärnken wir uns in diesem Teil auf das sogenannte Extractive Question Answering. 2 3 4
Nun wollen wir uns ein kurzes Beispiel zu diesem Problem ansehen. Hierzu geben wir ein Bild vor, welches wir von dieser Quelle bezogen haben.
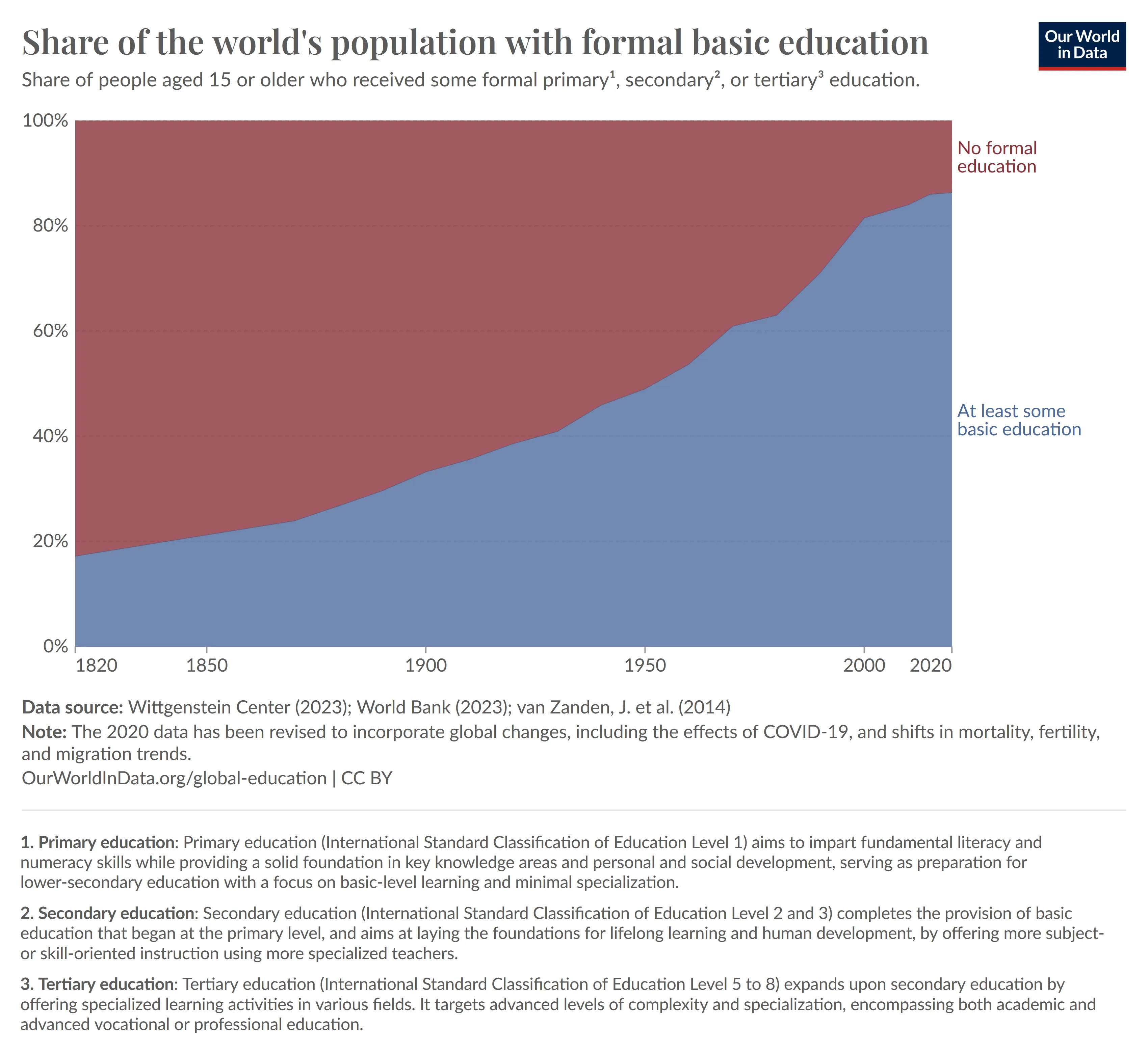
Eine mögliche Frage, welche wir zu diesem Bild haben könnten, wäre beispielsweise “Wie hoch ist der Anteil aller Menschen, welche eine formale Grundbildung besitzen?”. Ein Blick in die Quelle zeigt uns, dass dieser Wert im Jahr 2020 exakt betrug. Abhängig von der notwendigen Genauigkeit könnte uns hier allerdings auch ein Wert wie ausreichen. Wir könnten allerdings auch Fragen stellen, welche beispielsweise auf die Steigung des Graphen des Anteils mit Grundbildung Bezug nehmen, oder uns erklären lassen was denn genau unter dem Begriff “Primary Education” hier verstanden wird.
Verwendung des Modells
Um das Modell zu implementieren, benötigen wir nur 9 Zeilen. Beginnen wir mit den Imports:
from transformers import Pix2StructProcessor, Pix2StructForConditionalGeneration
from PIL import Image
Anschließend können wir sowohl den Präprozessor als auch das neuronale Netz über die Transformers API von Huggingface herunterladen.
processor = Pix2StructProcessor.from_pretrained('google/matcha-chartqa')
model = Pix2StructForConditionalGeneration.from_pretrained('google/matcha-chartqa')
Der nächste Schritt besteht darin, das Bild über PIL in das Skript zu laden und einer Variablen eine Frage zuzuweisen.
image = Image.open("This is the path strin to the target image.")
question = "This is an example question, related to the image given."
Im letzten Codeabschnitt können wir die Vorverarbeitung des Bildes und der Frage mit Hilfe des processor starten. Danach können wir die verarbeiteten Eingaben an das Modell übergeben.
Im letzten Schritt verwenden wir wieder den processor, um die Rohdaten aus dem Modell zu verarbeiten und in eine lesbare Form zu bringen.
inputs = processor(images=image, text=question, return_tensors="pt")
predictions = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(predictions[0], skip_special_tokens=True))
Anwendungsbeispiele
Im Folgenden wollen wir die Möglichkeiten von Kosmos2 anhand einer Reihe von Beispielen vorstellen. Dazu werden wir verschiedene Grafiken verwenden und Fragen mit unterschiedlichem Schwierigkeitsgrad stellen. Zu allen Statistiken verlinken wir weiterhin die Quelle, um allen Nutzer:innen unserer Seite die Quelle der Statistiken direkt zur Verfügung zu stellen.
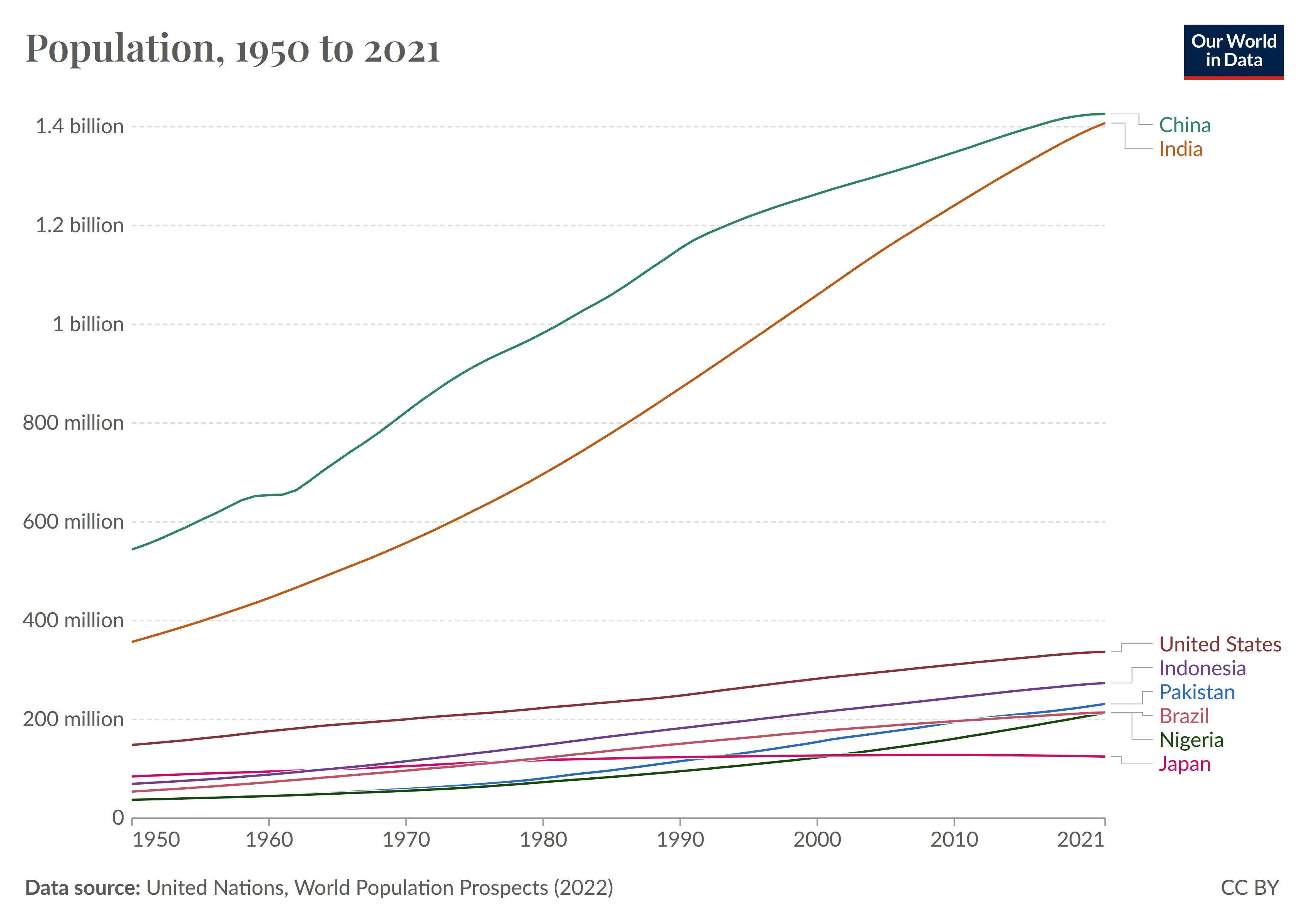
Fragestellung: Which country had the highest population in the year 2000?
Antwort: China
Fragestellung: Which country had the highest population growth in the year 2000?
Antwort: China
An diesem Bild kann man erkennen, dass die grundsätzlichen Fragen nach bestimmten Werten und deren Rangfolge durchaus richtig sind, die Veränderungen der Werte aber nicht immer. Die richtige Antwort auf die zweite Frage wäre Indien gewesen.
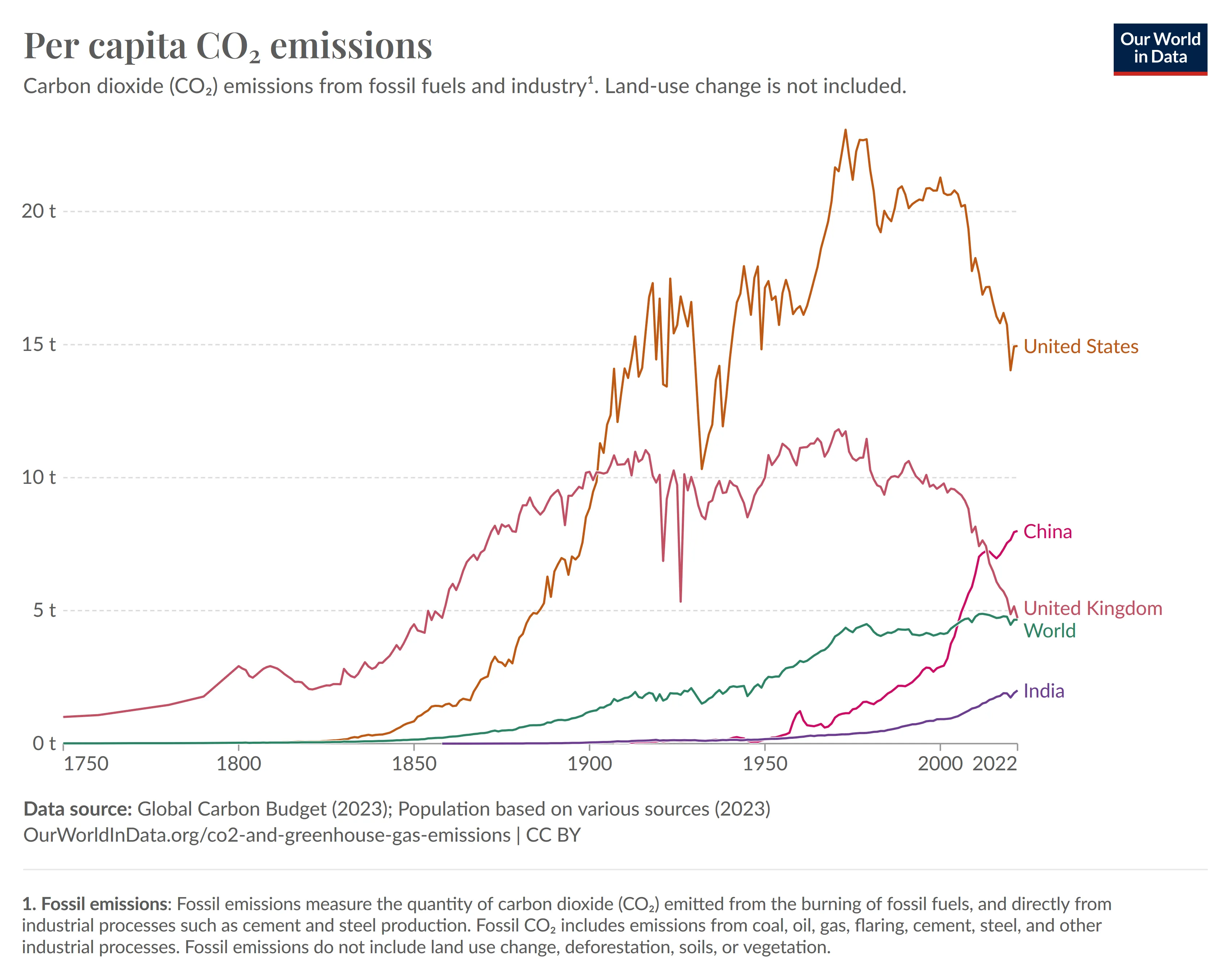
Fragestellung: In which year did the United Kingdom hit 5t the first time?
Antwort: 1800
Fragestellung: Which country has the lowest emissions in the year 2022?
Antwort: India
Auch in diesem Bild sehen wir, dass die grundsätzlichen Rangfolgen wieder richtig analysiert werden. Allerdings weicht hier die Jahreszahl relativ stark von der tatsächlichen Antwort ab - die Antwort auf die erste Frage dürfte eher in Richtung 1860 gehen.
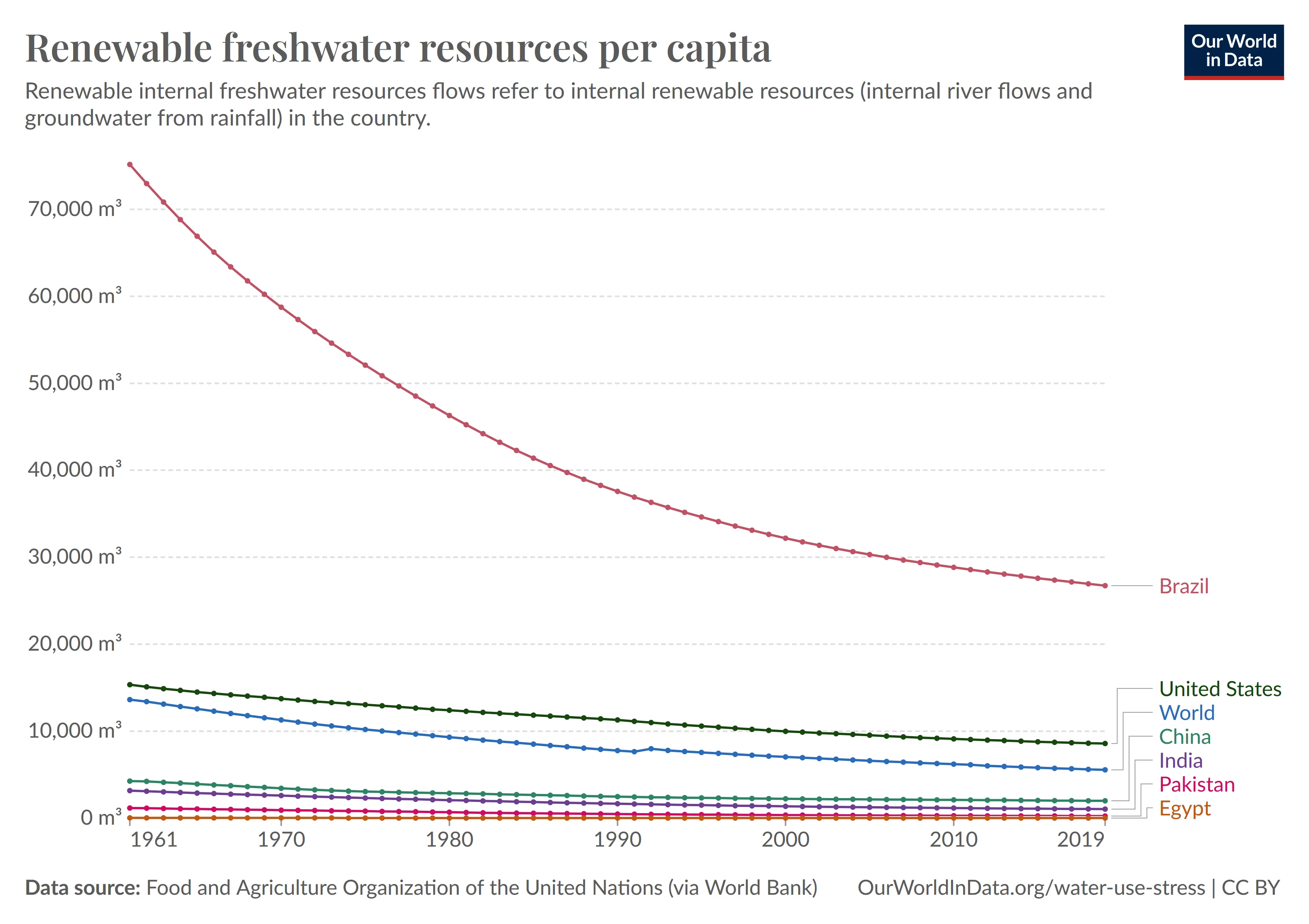
Fragestellung: Which country had the steepest decline in renewable freshwater resources between 1980 and 1990?
Antwort: Brazil
Durch die Verwendung des nächsten Bildes wollen wir aufzeigen, dass Matcha-Quarta auch die Fähigkeit zur Übertragung von Informationen hat, welche nicht direkt im Bild gegeben sind.
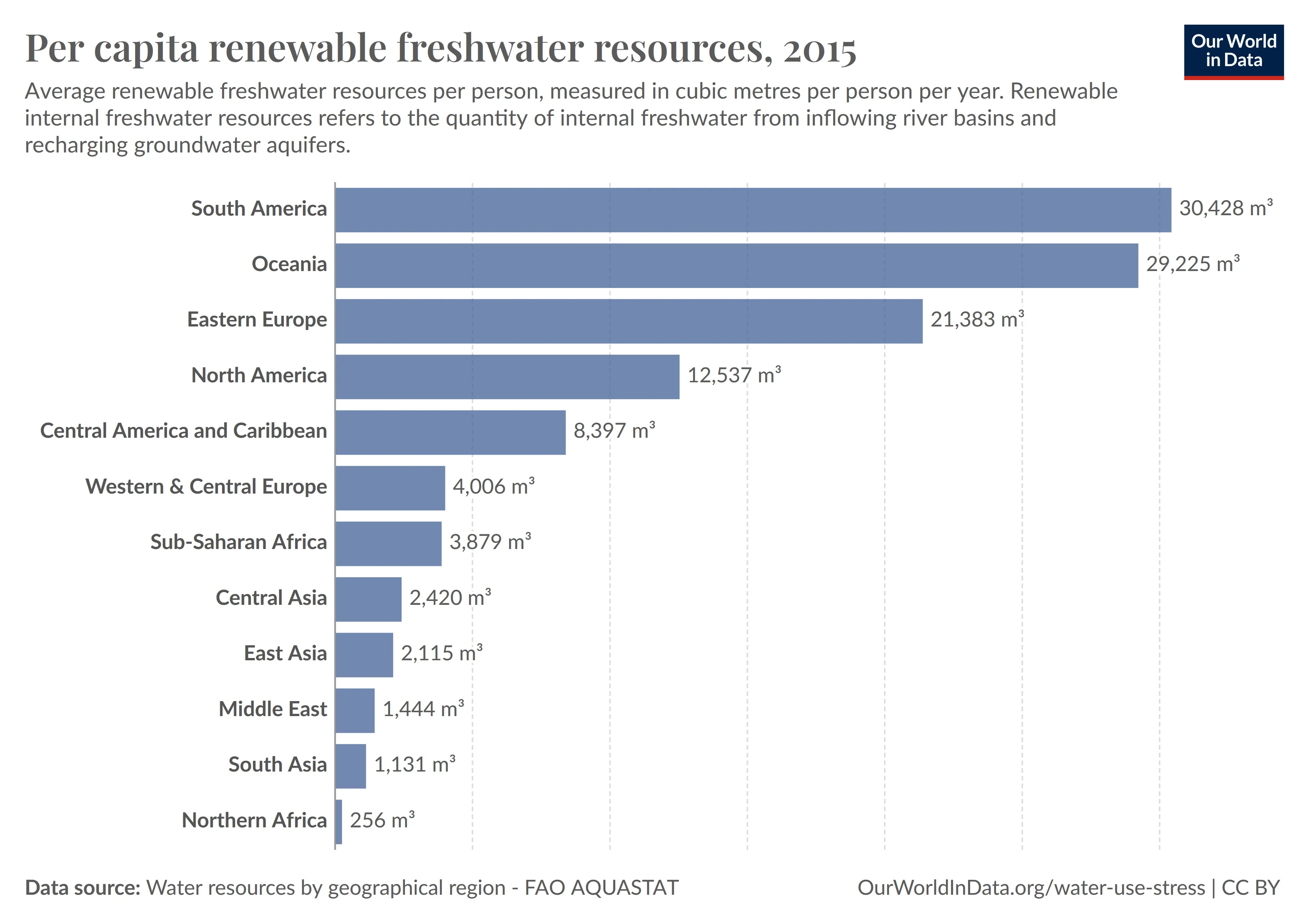
Fragestellung: What amount of renewable freshwater reserves did India have in the year 2019?
Antwort: 1.131
Obwohl Indien in dem Bild nie unter “South Asia” definiert wurde, war es Matcha-Quarta möglich eine Übertragung dieses Wissens durchzuführen.
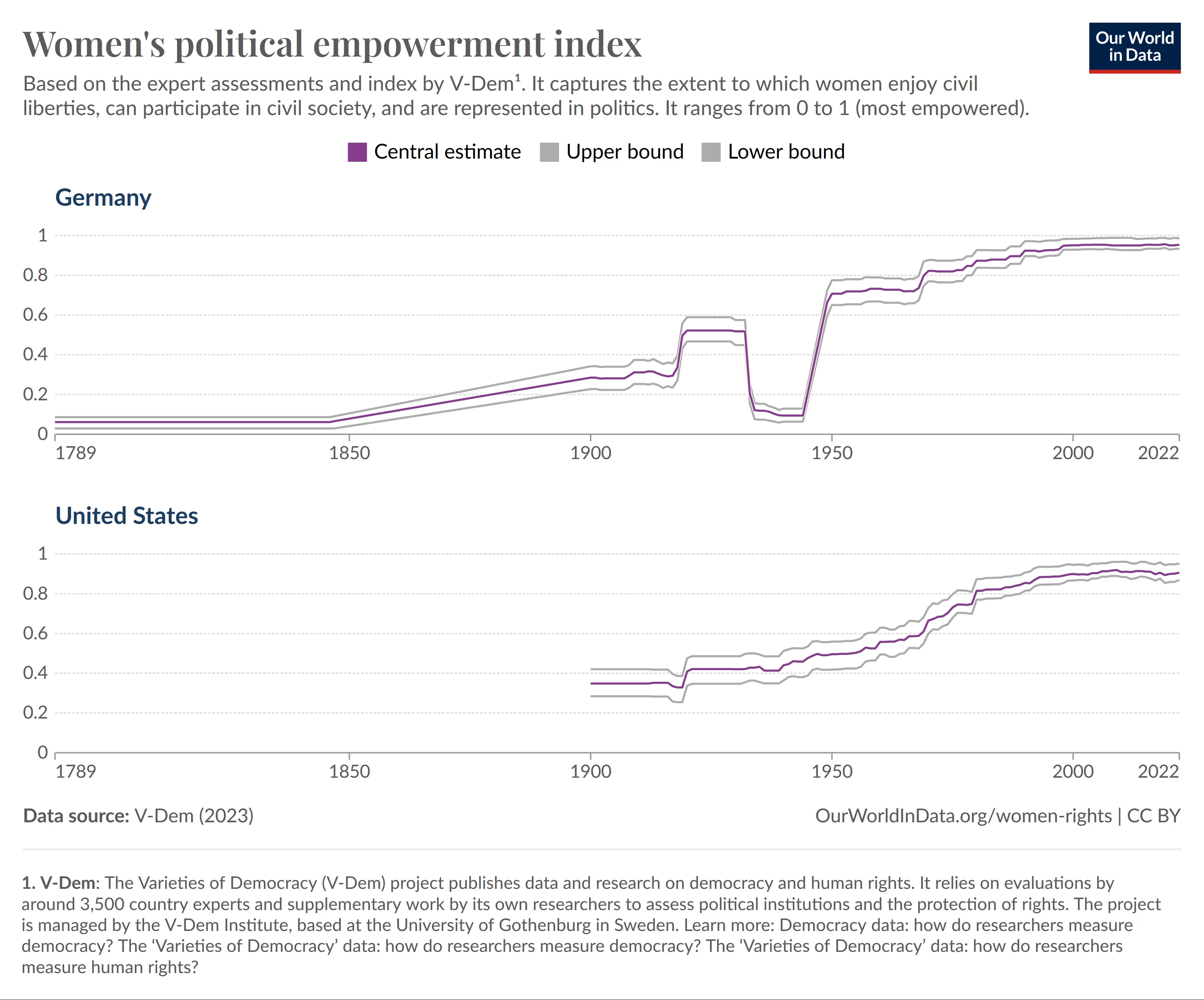
Fragestellung: Which country achieved a higher womens political empowerement index in the year 1950?
Antwort: Germany
Fragestellung: Which country achieved a higher womens political empowerement index in the year 2000?
Antwort: Germany
Dieses Bild zeigt im Vergleich zu den vorherigen Ergebnissen, dass Matcha-Quarta am Ende eines Zeitintervalls häufiger Probleme mit der Einstufung hat, während es am Ende des Zeitintervalls häufig (deutlich) bessere Ergebnisse erzielt. Die Antwort für das Jahr 1950 sollte “United States” (oder ähnlich) lauten.
Nun wollen wir auch aufzeigen, dass Matcha-Quarta auch in der Lage ist, mit relativ komplexen Datenlagen umzugehen. Hierzu verwenden wir das folgende Bild:
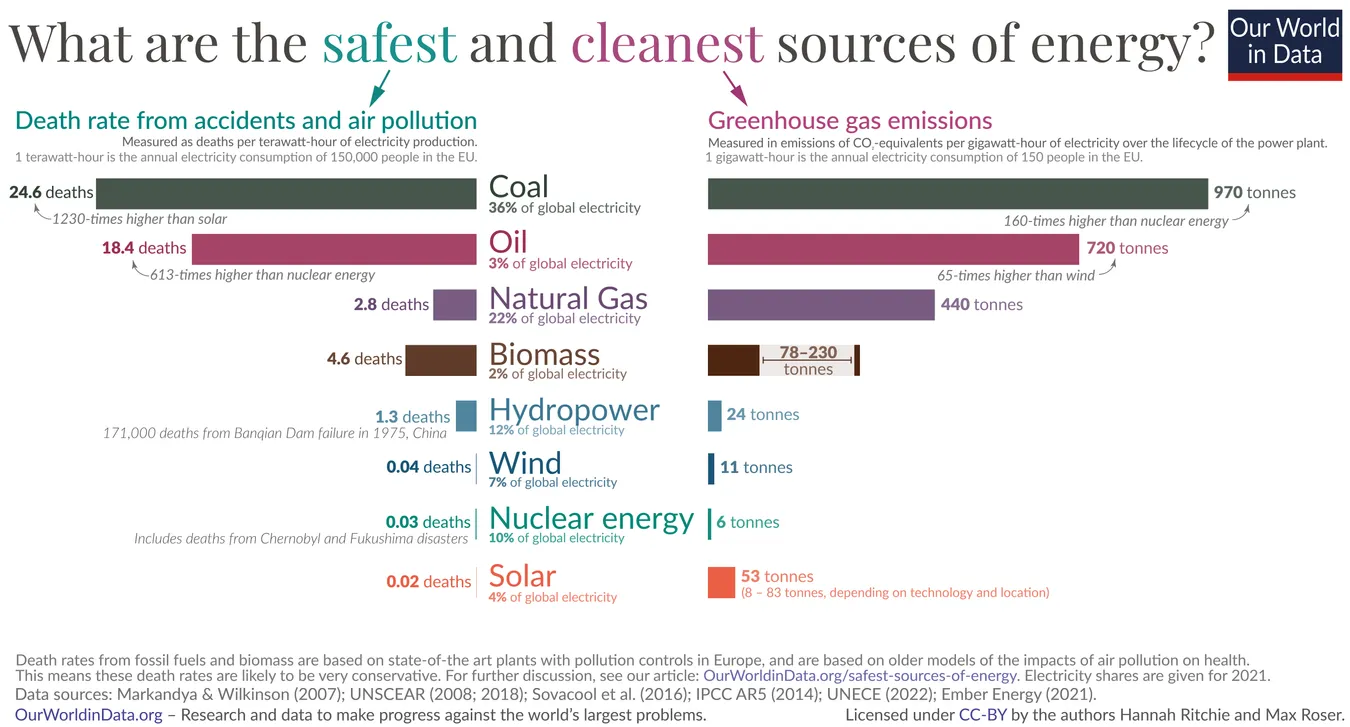
Fragestellung: How many times more CO2 is produced by coal compared to nuclear energy?
Antwort: 160
Fragestellung: What type of energy source is the safest source of energy?
Antwort: [Solar, Greenhouse gas]
Fragestellung: What type of energy source is the cleanest source of energy?
Antwort: [Solar, Greenhouse gas]
Wir können sehen, dass die erste Antwort richtig ist. Bei den beiden anderen Fragen erhalten wir jedoch jeweils zwei Antworten, obwohl aus dem Bild eindeutig hervorgeht, dass nur eine Antwort richtig sein kann. Bei der ersten Antwort ist jedoch Solarenergie angegeben, was die richtige Antwort ist. Bei der dritten Frage haben wir schließlich nur falsche Antworten.
Fehlerhafte Ergebnisse
Auch wenn wir weiter oben schon einige Beispiele mit Fehlern gezeigt haben, wollen wir in diesem Abschnitt einmal Anfragen zeigen, die besonders auffällige Fehler aufweisen. Wir beginnen mit dieser Statistik:

Zu diesem Bild haben wir die folgenden Fragen gestellt:
Fragestellung: Which country had the highest percentage of nuclear energy consumed?
Antwort: Mexico
Fragestellung: Which country had the highest percentage of nuclear energy consumed across europe?
Antwort: China
Fragestellung: Please describe the “substitution method” in a single sentence.
Antwort: 2
Diese Antworten haben wir nicht unbedingt kommen sehen. Tatsache ist, dass die Antwort “2” auf die letzten beiden Fragen keinen Sinn ergibt, auch die Variation der ersten Fragen (mit und ohne Zusatz “in Europa”) ist weit von der Wahrheit entfernt. Leider ist vor allem die Antwort “China” im Kontext “in Europa” völlig falsch.
Eine ähnliche Qualität der Ergebnisse haben wir mit dem nächsten Bild erreicht.
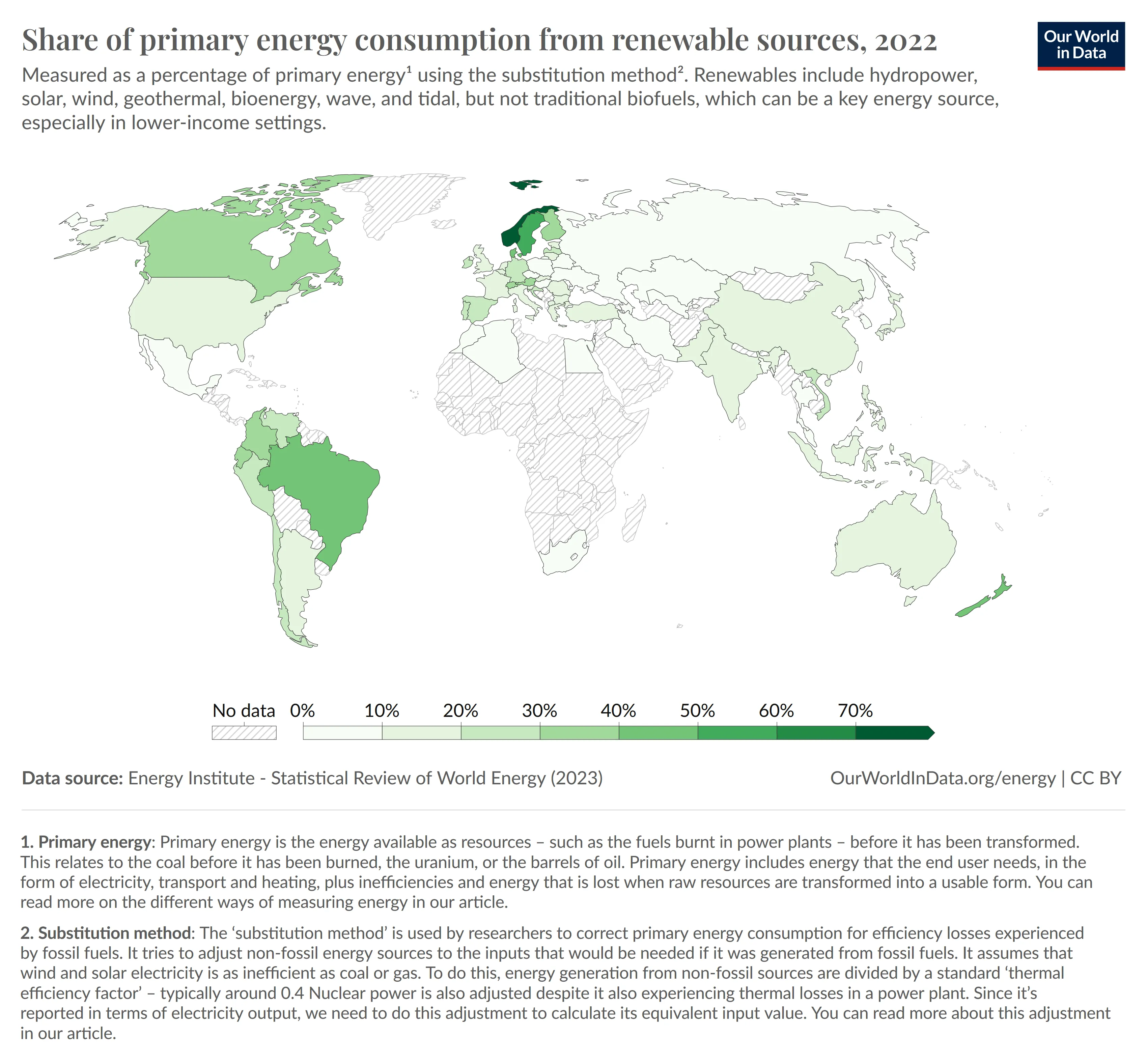
Fragestellung: Which country had the highest share of renewable energy generation in europe?
Antwort: Germany
Auch hier haben wir verwirrende Ergebnisse erhalten, allerdings liegt Deutschland - im Vergleich zur vorherigen Antwort - in Europa. Die richtige Antwort wäre hier Norwegen gewesen.
Unserer Erfahrung nach ist Matcha-Quarta noch nicht in der Lage, verlässliche Auswertungen aus Landkarten zu ziehen.
Anwendungsgebiete
Die Fähigkeit, automatisiert Fragen zu Bildern zu beantworten, kann sowohl für Einzelpersonen als auch für Unternehmen aus verschiedenen Gründen nützlich sein:
-
Zeitersparnis: Die automatisierte Bildanalyse kann schneller durchgeführt werden als manuelle Analysen, was Zeit spart. 5
-
Skalierbarkeit: Es ermöglicht die Verarbeitung großer Mengen von Bildern, was manuell nicht praktikabel wäre. 5
-
Zugänglichkeit: Es kann Menschen helfen, die Schwierigkeiten beim Sehen oder Verstehen von Bildern haben. Zum Beispiel können blinde oder sehbehinderte Menschen durch die Beschreibung von Bildinhalten unterstützt werden. 5
-
Datenanalyse: Unternehmen können diese Technologie nutzen, um Einblicke aus Bildern zu gewinnen, die für ihre Geschäftsziele relevant sind. Beispielsweise können Einzelhändler automatisierte Bildanalysen verwenden, um die Produktplatzierung in ihren Geschäften zu optimieren. 6
-
Sicherheit und Überwachung: In Sicherheits- und Überwachungsanwendungen können automatisierte Bildanalysen dazu beitragen, verdächtige Aktivitäten zu erkennen und entsprechende Warnungen auszulösen.
-
Gesundheitswesen: Im Gesundheitswesen können automatisierte Bildanalysen dazu beitragen, Krankheiten zu diagnostizieren und Behandlungen zu überwachen, indem sie medizinische Bilder analysieren. 7
Diese Fähigkeit eröffnet eine Vielzahl von Anwendungsmöglichkeiten und kann einen erheblichen Mehrwert bieten. Es ist jedoch wichtig zu beachten, dass die Genauigkeit und Nützlichkeit der automatisierten Bildanalyse von der Qualität der verwendeten Algorithmen und Daten abhängt.
TL;DR
Die Grundidee hinter Kosmos2 ist relativ einfach - in der Anfangsphase von effizienten “Question Answering”-Modellen können wir ein relativ kleines neuronales Netz mit einem Tokenizer verwenden, um uns Fragen zu Bildern automatisiert beantworten zu lassen. Auch wenn bisher nur relativ einfache Fragen mit guter Wahrscheinlichkeit beantwortet werden können, kann Kosmos2 eingesetzt werden, um alltägliche Aufgaben mit Bildern zu automatisieren oder den Menschen bei Aufgaben mit Bildern besonders effizient zu machen. Bei komplexeren Fragen konnten wir zeigen, dass häufig Antworten ausgegeben werden, die leider nichts mit der eigentlichen Frage oder dem Bild zu tun haben.
In (naher) Zukunft erwarten wir Modelle, die bei dieser Aufgabe deutlich bessere Antworten liefern. Wann genau, wird sich sicher bald zeigen.