
Einordnung
Bei der Arbeit mit neuronalen Netzen gibt es verschiedene Schwierigkeiten, gute Performance zu erzielen. Die Performance eines Modells - wie auch immer diese definiert ist
- hängt hierbei von verschiedenen Faktoren ab, beispielsweise die Menge an Informationen welche verwendet wird, die Häufigkeit des Trainings (Epochen) oder auch die Architektur und Parameter des Modells. Vor allem für die Architektur und Parameter des Modells wird Hyperparameteroptimierung verwendet, da der Search Space zu groß ist, um diesen mit einer klassischen Grid Search zu durchsuchen. 1
Bei dem Search Space handelt es sich um die Gesamtmenge alle Möglichkeiten der verschiedenen, einzelnen Parameterwerte.
Grundlagen
Was ist das Ziel einer Hyperparameteroptimierung?
Ziel unserer Hyperparameteroptimierung ist es, eine Konfiguration von Parametern zu finden, welche eine optimale Konfiguration des Modells bezüglich der Performance zu finden. Häufig werden wir aber nur eine gute Konfiguration finden.
Wir finden meist nur eine gute Konfiguration, da die Optimierung von neuronalen Netzen eine unheimlich komplexe und mathematisch nicht-lineare Aufgabe ist. Dies ist immer noch besser als keine Optimierung; mehr Zeit in der Optimierung wird üblicherweise immer noch leicht bessere Ergebnisse liefern.
Hyperparameteroptimierung eines DQN’s
Ein grundsätzlich komplexeres Beispiel (welches in Machine Learning eher der Fall ist) wäre die Hyperparameteroptimierung eines Deep Q-Networks. Die Basis hierfür stellt die Implementierung des Deep Q-Networks, so wie es vor einer Woche präsentiert wurde. Die Imports sind in diesem Fall wie folgt:
import numpy as np
import tensorflow as tf
import gym
import optuna
import joblib
import sys
import datetime
from os.path import exists
from dqn_agent import DQNAgent, training_loop, evaluation_run
Joblib ist eine Library für das Speichern von den Studies aus Optuna-Iterationen.
Es werden anschließend eine Reihe globaler Variablen definiert, welche Informationen für verschiedene Funktionen beinhalten:
max_frames_episode, avg_length = 500, 50
n_episodes = 5000
env_name = "CartPole-v1"
opt_rounds, final_rounds = 50, 150
Anschließend wird die objective-Funktion definiert:
def objective(trial):
env = gym.make(env_name)
n_actions = env.action_space.n
observation_shape = env.observation_space.shape[0]
agent = DQNAgent(observation_shape, n_actions, trial)
env.seed(69)
tf.random.set_seed(69)
np.random.seed(69)
for current_episode in range(n_episodes):
episode_reward, agent = training_loop(env, agent, max_frames_episode)
# Write episodic score to tensorboard database
with agent.score_writer.as_default():
tf.summary.scalar('Episodic Score', episode_reward, step=current_episode)
agent.train()
# Criterion to maximize: Mean score over a specified amount of episodes (true evaluation, without epsilon-greedy)
scores = np.zeros((opt_rounds,))
for i in range(opt_rounds):
scores[i], agent = evaluation_run(env, agent, max_frames_episode)
# Write evaluation score to tensorboard database
with agent.score_writer.as_default():
tf.summary.scalar('Evaluation Score', scores[i], step=i)
return np.mean(scores)
In dieser Funktion passieren mehrere Dinge:
- Initialisierung des Agenten und Seeds
- Training des Agenten
- Evaluierung des Agenten mittels
evaluation=True.
Der Seed ist ein Wert für die Initialisierung eines Pseudo-Zufallszahlen-Generators, wie dieser in nahezu allen Computeranwendungen verwendet wird (so auch Gym, Tensorflow und Numpy).
Nach dieser Funktion werden Hyperparameter ausgewählt, welche (unter dem Seed) die besten Ergebnisse liefern. Es wäre möglich, den Seed zu entfernen, um potentiell andere Ergebnisse zu erzielen.
Anschließend kann noch eine Funktion definiert werden, um die Konfiguration mit den besten Parametern ohne Seed zu trainieren. Hierbei werden mehrere Agenten trainiert und die beste Iteration zurückgegeben.
def detailed_objective(trial):
env = gym.make(env_name)
n_actions = env.action_space.n
observation_shape = env.observation_space.shape[0]
agent = DQNAgent(observation_shape, n_actions, trial)
file.write("Starting Training of Trial {} ... \n".format(trial.number))
for current_episode in range(n_episodes):
episode_reward, agent = training_loop(env, agent, max_frames_episode)
# Write episodic score to tensorboard database
with agent.score_writer.as_default():
tf.summary.scalar('Episodic Score', episode_reward, step=current_episode)
agent.train()
# Criterion to maximize: Mean score over a specified amount of episodes (true evaluation, without epsilon-greedy)
scores = np.zeros((final_rounds,))
for i in range(final_rounds):
scores[i], agent = evaluation_run(env, agent, max_frames_episode)
# Write evaluation score to tensorboard database
with agent.score_writer.as_default():
tf.summary.scalar('Evaluation Score', scores[i], step=i)
return np.mean(scores), agent # Also return agent to save if this agent has highest score
Letztlich fehlt noch die Initialisierung der Hyperparameteroptimierung und Zwischenspeicherung von Ergebnissen:
if __name__ == "__main__":
iteration = sys.argv[^medium]
study_name, study_path = "DQN_CartPole", "study_dqn_cartpole{}.pkl".format(iteration)
number_trials, amount_iterations = 5, 100
study = None
try:
for i in range(amount_iterations):
if (exists(study_path) == False):
study = optuna.create_study(study_name=study_name, direction="maximize")
else:
study = joblib.load(study_path)
study.optimize(objective, n_trials=number_trials)
joblib.dump(study, study_path)
trial = study.best_trial
print("Mean Score of the best Trial: ", trial.value)
print("Parameters of the best Trial: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))
# Train another set of networks with the best hyperparameters and select the network with the highest average score
num_iterations = 10
agents, rewards = [], []
for i in range(num_iterations):
score, agent = detailed_objective(trial) # Train with best trial
rewards.append(score)
agents.append(agent)
rewards = np.array(rewards)
best_agent_v = np.argmax(rewards)
best_agent = agents[best_agent_v]
best_agent.model.save_model("optimization/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
except Exception as e:
logname = "log{}.txt".format(iteration)
if (exists(logname) == False):
f = open(logname, "w")
else:
f = open(logname, "a")
file = f
file.write(str(e))
file.close()
Eine Zwischenspeicherung von Ergebnissen kann notwendig sein, da eine Hyperparameteroptimierung unter Umständen sehr lange dauern kann. Ein
try-catch-Block wurde hierbei eingerichtet, um unter Umständen Fehler abzufangen und diese auslesen zu können. Dies ist vor allem vorteilhaft bei der Ausführung auf Virtual Machines wie Google Colab im nicht-interaktiven Modus.
Die Anzahl der maximalen Trials pro Iteration und Anzahl der Iterationen sind hierbei sehr groß. Eine realistische Suche wird klassisch lange nicht so viele Iterationen benötigen. Eine Hypothese hierbei könnten auch 200 Iterationen insgesamt sein.
Visualisierung der Ergebnisse
Für die Visualisierung von Optimierungs-Ergebnissen hat Optuna verschiedene Funktionalitäten, welche unter dem Modul optuna.visualization laufen.
import optuna
import joblib
study = joblib.load("study_dqn_cartpole.pkl")
Eine Ausgabe des besten Wertes und der dazugehörigen Hyperparameter ist auf eine sehr einfach Art möglich:
print("---Evaluation: Best Trial---")
trial = study1.best_trial
print("Mean Score of the best Trial from study: ", trial.value)
print("Parameters of the best Trial: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))
Es gibt eine Reihe von Visualisierungen, welche sehr nützlich sind. Diese werden im Folgenden einmal beispielhaft demonstriert, an einer Studie mit insgesamt 100 Iterationen.
plot_optimization_history:
from optuna.visualization import plot_optimization_history
plot_optimization_history(study)
plot_param_importances
from optuna.visualization import plot_param_importances
plot_param_importances(study)
plot_contour:
from optuna.visualization import plot_contour
plot_contour(study, params=["Gamma Parameter", "Epsilon Parameter"])
Hier können verschiedene Parameter aus der Definition der Hyperparameter verwendet werden. Die Anzahl der Parameter ist begrenzt auf genau zwei Parameter.
Alternativ können alle Parameter in einem Plot visualisiert werden, indem das Argument
paramsnicht verwendet wird.
Weitere Möglichkeiten von Optuna
Sampler
Die Optimierungen, welche bisher gestartet sind, waren von den Ergebnissen her gut, allerdings noch nicht optimal. Dies liegt in Teilen daran, dass bisher lediglich der Standard-Sampler von Optuna verwendet wurde, welche nicht unbedingt an das Problem angepasst war.
Ein Sampler ist ein Algorithmus, welcher für das Vorschlagen der Parameter der aktuellen Iteration zuständig ist.
Durch Verwendung eines angepassteren Samplers verbessert sich die unter Umständen die Effizienz der Optimierung. Eine Reihe von implementierten Samplern kann man im Bild unten sehen.
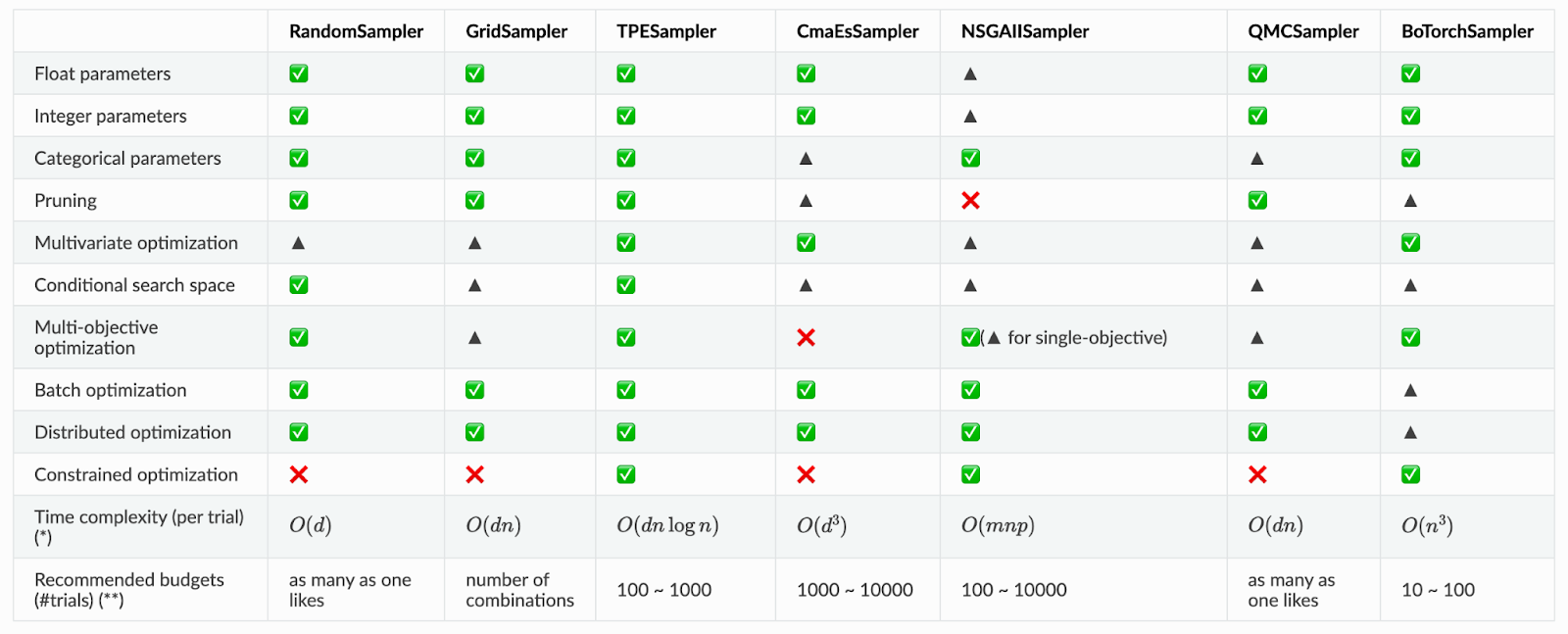
-
✅: Feature wird unterstützt
-
▲: Funktioniert, allerdings ineffizient
-
❌: Fehlerbehaftet oder besitzt kein entsprechendes Interface.
-
: Dimension vom Search Space
-
: Anzahl der fertiggestellten Trials
-
: Anzahl der zu optimierenden Ziele
-
: Größe der Population (algorithmisch-spezifisch)
Es ist erkennbar, dass beispielsweise der TPESampler ein guter Sampler für die implementierten Probleme ist. Die Dokumentation nutzt diesen als standardmäßigen Sampler. 2
Pruner
Es besteht die Möglichkeit, mehrere verschiedene Pruning-Algorithmen zu verwenden, um (angepasst auf den Sampler) die Zeiteffizienz der Optimierung zu steigern. Mehr dazu hier.
Ein Pruner ist ein Algorithmus, welcher für das frühe Abbrechen von wenig erfolgsversprechenden Iterationen zuständig ist.
Beschränkte Optimierung
Ebenfalls besteht die Möglichkeit, Optimierung auf beschränkten Mengen oder Gebieten durchzuführen. Dazu existiert ein Beispiel hier.
Weitere Visualisierungen
Optuna ist nicht nur eine gute Plattform für Optimierung von komplexen Problemen, sondern besitzt seit kurzer Zeit auch seine eigene Visualisierungsumgebung äquivalent zu Tensorboard. Diese kann man hier finden.
Weitere Informationen
Grundsätzlich zielt diese Einführung auf Reinforcement Learning ab, kann allerdings äquivalent auch für Supervised Learning angewandt werden. Für Supervised Learning existieren allerdings noch eine Reihe anderer Optimierungsalgorithmen, welche dort (teilweise) effizienter sind. Als klassisches und einfaches Beispiel hierfür ist der Keras Hyperband-Tuner anzusehen.
Weiterhin existieren noch eine Reihe anderer Hyperparameter-Optimierungs-Libraries, beispielsweise Hydra oder viele andere Möglichkeiten. 3
Änderungen
- [27.03.2023] Einfügen interaktiver Plots, entfernen von weniger wichtigeren Plots um besser auf relevante Plots aufmerksam zu machen.